A new study out of Microsoft Research reveals that even the most polished AI models—including Anthropic’s Claude 3.7 Sonnet and OpenAI’s o3-mini—can’t debug code as reliably as a human.
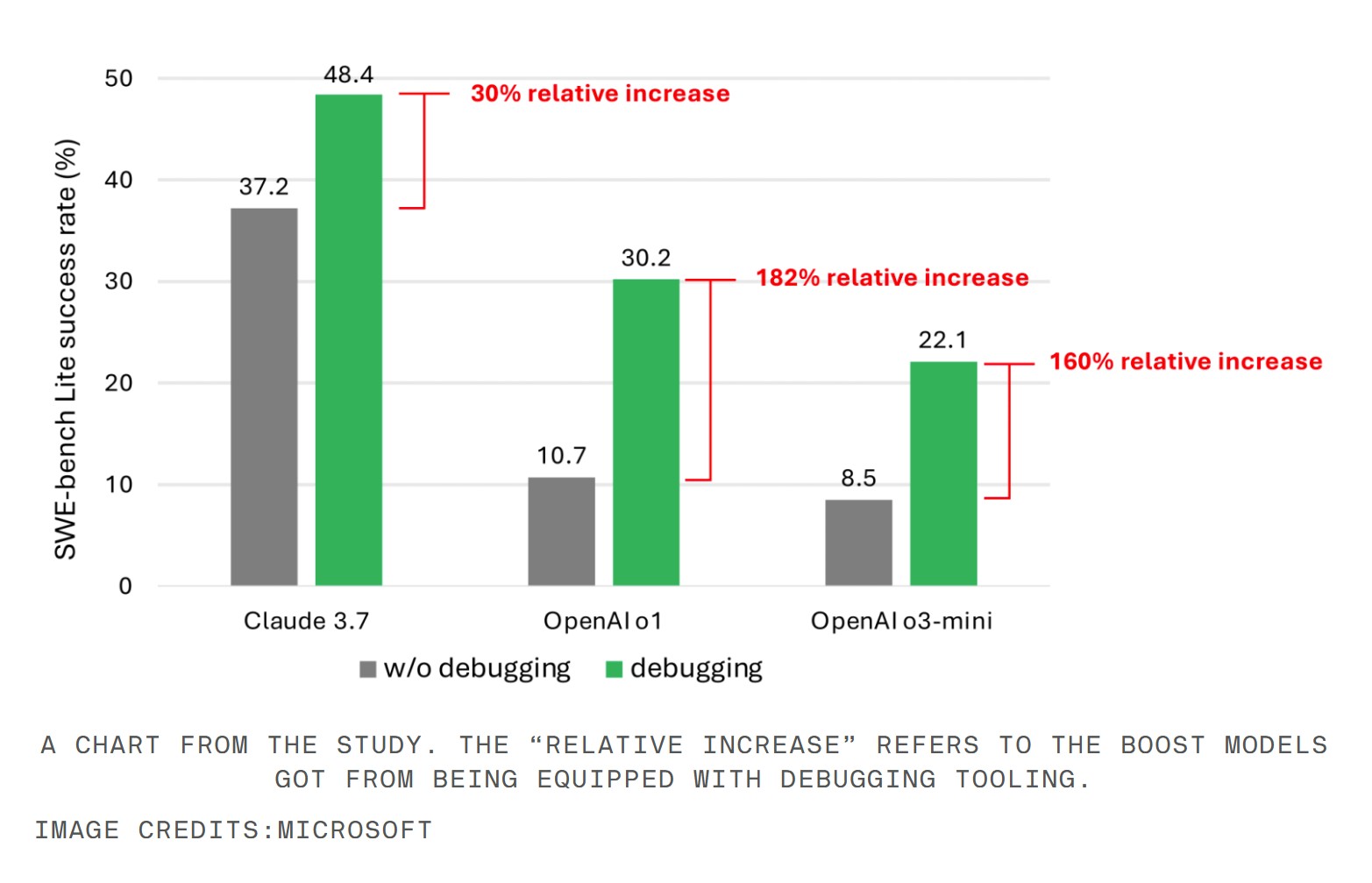
Researchers tested nine different models using a “single prompt-based agent” setup, handing them 300 curated debugging tasks from the SWE-bench Lite benchmark and access to tools like a Python debugger. Claude 3.7 Sonnet topped out at 48.4 per cent accuracy, OpenAI’s o1 hit 30.2 per cent, and o3-mini limped in with a meagre 22.1 per cent.
The models reportedly bungled the use of basic debugging tools and didn’t seem to grasp which tools were right for which problems. The root of the issue, researchers say, is a lack of training data that shows real developers fixing real bugs. There’s a serious shortage of “sequential decision-making processes”—in other words, the kind of logic-trace humans naturally follow when sorting out broken code.
“We strongly believe that training or fine-tuning [models] can make them better interactive debuggers,” wrote the study’s co-authors, but they stressed that this would need properly labelled interaction data—something AI models are sorely lacking.
This isn’t the first sign AI’s coding chops aren’t all they’re cracked up to be. Other reports have flagged that AI-generated code can be riddled with bugs and security holes. Devin, the much-hyped AI dev tool, recently flunked a programming test, managing just three out of 20 tasks.
Microsoft’s deep dive might not scare off investors who are still throwing billions at AI-powered code monkeys, but it should give bosses and engineers alike a reason to pause before trusting the bots with anything mission-critical.
Even as the cocaine nose jobs of Wall Street, and valley hype merchants keep talking up AI’s takeover, some high-profile tech heads are sounding more grounded. Microsoft founder Bill Gates, Replit CEO Amjad Masad, Okta’s Todd McKinnon, and IBM’s Arvind Krishna all reckon programming isn’t going anywhere. At least, not yet.